- My research connects the concepts and methods of social networks and the semantic web with machine learning and natural language processing. I am interested in combining human intelligence with artificial intelligence methodologies. I am specifically interested in methods that bridge the areas of connectionism and symbolics models applied to real-world applications (see Publications and PhD-Thesis)
- October 2010 – December 2011: Post-doctoral research at Artificial Intelligence Group at Bielefeld University at the Excellence Cluster 277 (CITEC) project Knowledge Enhanced Embodied Cognitive Interaction Technologies (since October 2009 affiliated to the Center of Excellence Cognitive Interaction Technology).
- November 2010, PhD in Computer Science from the Technical Faculty at Bielefeld University. PhD was advised by Prof. Dr. Alexander Mehler in the Text Technology Group, and co-adviser Prof. Dr. Ipke Wachsmuth in the Artificial Intelligence Group.
- 2007 to 2010: Research Scientist Text Technology and Applied Computational Linguistics Department at Bielefeld University.
- 2004 to 2007: Master of Science from the University Bielefeld –Bertelsmann-Scholarship for Thesis.
- 2001 to 2004: Bachelor of Arts (hon) from the University of Middlesex London
Research Group PhDs
- Usama Yaseen, LMU Germany, (Advisor: Pankaj Gupta), 2019 – x
- Yatin Chaudhary, LMU Germany, (Advisor: Pankaj Gupta), 2019 – x
- Pankaj Gupta, LMU Germany, (Advisor: Hinrich Schuetze), 2016 – 2019
- Sanjeev Kumar Karn, LMU Germany, (Advisor: Hinrich Schuetze), 2016 – 2019
Supervision
- Sanjeev Kumar Karn (Master): From Information Extraction to Knowledge Graph Construction: A Machine Learning and Statistical Approach on Industrial Data, 2016
(Advisor: Prof. Dr. Thomas Runkler) – TU Munich - Malte Sander (Master): Ontology-based translation of natural language queries to SPARQL, 2014
(Advisor: Prof. Dr. Thomas Runkler) – TU Munich - Artem Ostankov (Master): Integrating Machine Learning and Semantic Network techniques for Question Answering over the Linked Data Cloud, 2014
(Advisor: PD Dr. Florian Röhrbein) – TU Munich - Thomas Meyer (Master): Ein qualitativer Ansatz zur Analyse von Clickstream Data als Ergänzung zu bestehenden Analyseverfahren, 2011
(Advisor: Dr. Hans-Jürgen Eikmeyer) – Bielefeld University - Jan Laußmann Kubina (Diplom): System zur Analyse von Zeitreihen, 2010
(Advisor: Prof. Dr. Alexander Mehler) – Bielefeld University - Petra Kubina (Master): Annotationsschema zur qualitativen Inhaltsanalyse metasprachlicher Äußerungen von Laien in Spracheinstellung und Sprachwissen, 2010
(Advisor: Prof. Dr. Jan Wirrer) – Bielefeld University -
Tobias Feith (Bachelor): Interaktive Visualisierung Sprachlicher Netzwerke, 2010
(Advisor: Dr. Hans-Jürgen Eikmeyer) – Bielefeld University

Teaching
- Intelligent Information Retrieval (SS 2011)
Ulli Waltinger & Ipke Wachsmuth
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=22847336 - Representation and processing of multimodal documents (SS 2010)
Alexander Mehler & Ulli Waltinger & Peter Menke (practical)
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=16965464 - Texttechnology (WS 2009)
Alexander Mehler & Ulli Waltinger (practical)
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=14982298 - Digital terminology dictionary (SS 2008)
Maik Stührenberg & Ulli Waltinger
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=230138 - Structuring of information (SS 2007)
Alexander Mehler & Ulli Waltinger
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=1135051 - Digital terminology dictionary (SS 2007)
Olga Pustylnikov & Ulli Waltinger
eKVV: http://ekvv.uni-bielefeld.de/kvv_publ/publ/vd?id=3672588
Initatives
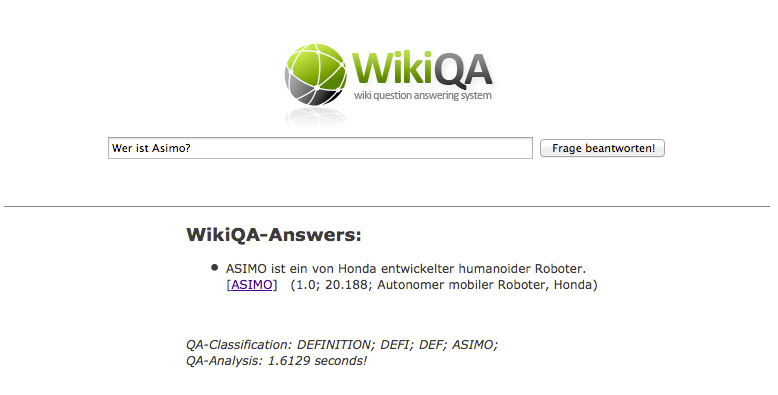
- Wikipedia Question Answering (WikiQA) WikiQA is a German open domain question answering system that uses the Wikipedia as a knowledge base to answer natural language questions. It has been developed by the KnowCIT project (Artificial Intelligence Group) within the CITEC at Bielefeld University. Using open domain encyclopedic information as a knowledge base, such as provided by the Wikipedia project, has captured the attention of QA researchers lately. However, most of the proposed Wikipedia-based QA systems focus primarily on the document collection of Wikipedia for answer retrieval, and thus disregard the complex hierarchical representation of knowledge by means of its category taxonomy, which can also be valuable in the context of QA systems. The WikiQA system approaches the Wikipedia collection from a different point of view. It exploits the use of the Wikipedia category taxonomy as a reference point for identifying the broader topic of a user’s question, in order to deduce from the topic a set of expected answer candidates. More precisely, it accesses and activates only those areas of our knowledge base which are primarily topically relevant to the questions subject.
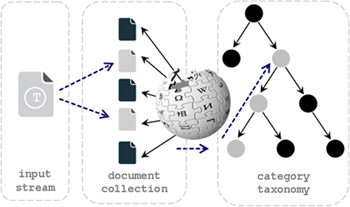
- Wikipedia OpenTopicModel Open Topic Model (OTM) is a text analysis tool written in C++ (Qt Development Frameworks) and ported to Java and Apache Lucene. It considers the problem of topic identification by means of Open Topic Models. That is, we are not heading towards a clustering of a document collection but labelling individual documents with the best fitting topic names obtained from a social ontology. The current OTM implementation utilizes over 55,000 different Wikipedia categories as topic labels and combines both keyword extraction as a type of text representation and categorization by means of topic labelling.
- German Polarity Clues A Lexical Resource for German Sentiment Analysis: Feel free to use/download the GermanPolarityClues dictionary A new publicly available lexical resource for sentiment analysis for the German language. The resource offers a number of 10.141 polarity features, associated to three numerical polarity scores, determining the positive, negative and neutral direction of specific term features
- eHumanities Desktop
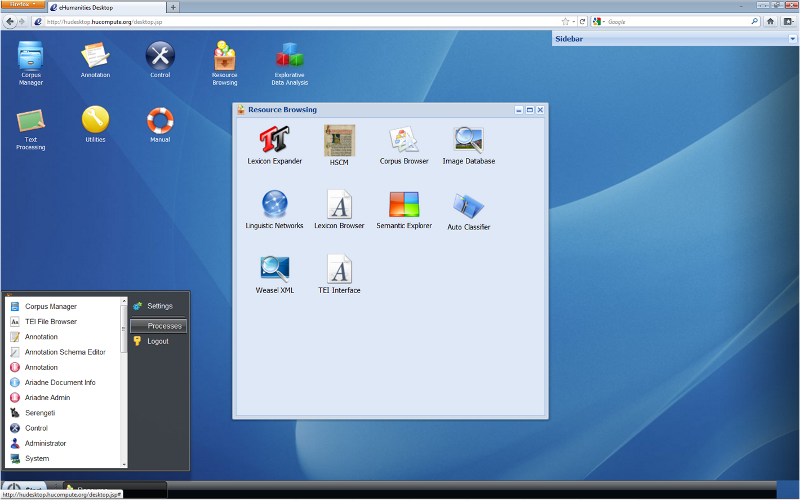
I was one of the Core-Developer in the developement (ExtJS/Java) of the Web-based Desktop System – The eHumanities Desktop.It allows to explore, process and analyse resources within an intuitive desktop environment – similar to the Windows Desktop. You can upload, organize, and share different resources and media, but also different computational linguistics applications such as classification, tagging or topic labeling (see hucompute.org for more information).





























{kind=link}
{kind=link}
{kind=link}
{kind=link}